电竞赛事分析:从数据中揭示英雄联盟全球总决赛的胜负
电子竞技赛事包括全球性的英雄联盟世界赛 #生活乐趣# #游戏乐趣# #电子竞技#
01赛事背景与预测
◇ 赛事背景介绍
当前,S10赛事即将拉开帷幕,各路选手摩拳擦掌,准备在召唤师峡谷一展身手。比赛初期,往往是决定胜负的关键时刻。那么,在这场万众瞩目的比赛中,究竟谁能抢占先机,在开局10分钟内就揭示胜负端倪呢?让我们拭目以待,共同见证这场精彩绝伦的赛事。2020英雄联盟全球总决赛(S10)已经成为电竞领域的焦点,比赛吸引了大量粉丝,且呈现出激烈的竞争态势,这为比赛初期预测胜负提供了背景。
2020英雄联盟全球总决赛(S10)正如火如荼地进行中,这场备受瞩目的国际电竞赛事,无疑吸引了众多英雄联盟玩家的目光。自9月25日入围赛开启以来,本次大赛便刷新了自S赛设立入围赛阶段赛事以来的纪录——首次实现了“无一队全败,无一队全胜”的均衡格局。这一独特纪录,不仅彰显了2020英雄联盟全球总决赛的激烈竞争,更预示着本届赛事将成为竞争最为激烈、看点十足的一届。

◇ 预测的重要性
当然,每场比赛的胜负是观众们最为关心的焦点,然而,在比赛初期,尤其是开局10分钟内,往往就能洞察出胜负的端倪。在比赛的开局10分钟内,往往能揭示胜负的端倪。通过分析历史数据,本文试图揭示关键因素。接下来,就让我们一起探寻那些能够预示胜负的关键时刻。
02游戏机制与数据分析
◇ 游戏机制概述
《英雄联盟》(League of Legends,简称LoL)是一款由拳头游戏(Riot Games)公司精心打造的多人在线竞技游戏。在游戏中,玩家们各自操控一位拥有独特技能的英雄,红蓝两队各派五位玩家展开激战,目标是摧毁对方的基地水晶。水晶受到多座防御塔的严密保护,因此玩家们通常需要先攻破数座防御塔才能触及水晶。
起初,玩家所操控的英雄实力较弱,但可以通过击杀小兵、野怪以及对方英雄来积累金币和经验。随着经验的增长,英雄的等级和技能等级也会提升;而金币则可用于购买装备,进一步增强英雄的攻击力、防御力等各项属性。
在战斗过程中,视野的控制至关重要。由于游戏机制设定,当己方单位不在附近时,该地点将陷入无视野状态,即无法观察到对面单位的动态。因此,双方玩家都会充分利用守卫来监视关键地点,从而洞悉对手的行动走向,为制定有效的战术提供依据。

◇ 数据分析与机器学习应用
本数据集来源于Kaggle平台,涵盖了钻一至大师段位的单双排位对局数据,为您深入解析这些对局提供有力支持。通过对9879场对局数据的分析,构建机器学习模型,预测比赛最终结果,尤其关注前10分钟的特征。
03数据处理与特征工程
◇ 数据导入与读取
假设数据文件存储在./data/目录中,对于标准的CSV文件,我们可以直接使用pandas库中的read\_csv()函数进行读取。接下来,我们将详细介绍如何使用这个函数来读取数据。使用pandas库导入和处理对局数据,为后续的数据分析和机器学习模型构建做准备。
◇ 数据概览与处理
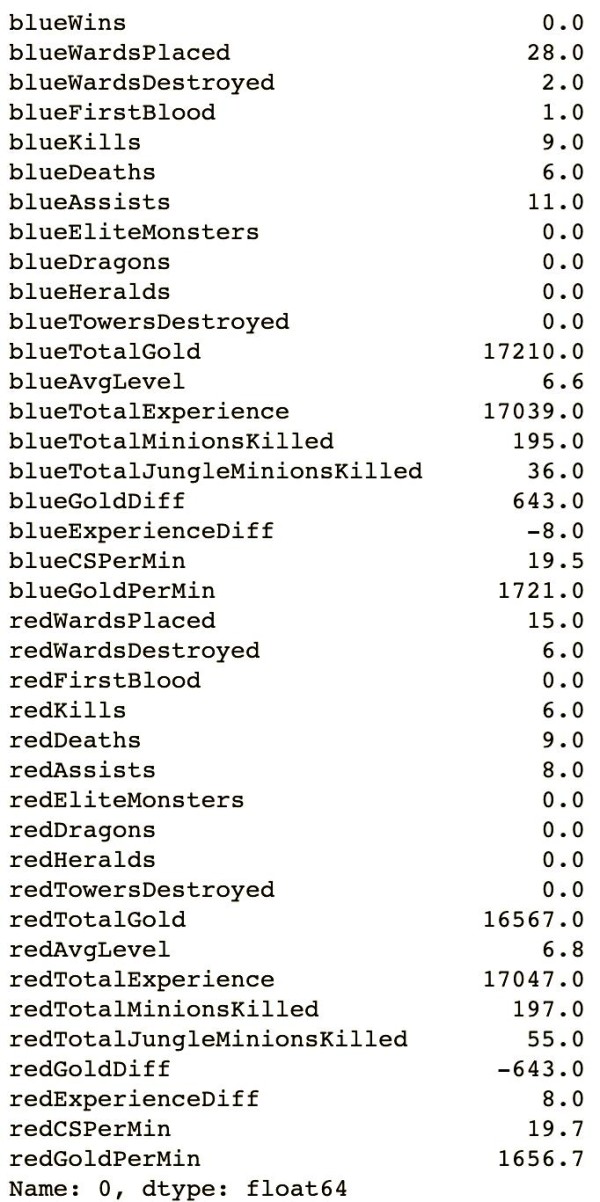
在处理机器学习问题时,了解数据的基本情况是至关重要的。我们可以使用pandas库中的方法,首先通过.iloc[0]取出数据的第一行进行初步观察。从输出的结果中,我们可以清晰地看到每个特征都是float64类型,即浮点数。这表明在蓝色方开局10分钟时,他们确实展现出了微小的优势。同时,我们也注意到某些特征列是冗余的,例如blueGoldDiff和redGoldDiff,这两个特征互为相反数,表示的是蓝色队和红色队的金币优势,显然是重复的。此外,还有如blueCSPerMin这样的特征,它表示蓝色方每分钟的击杀小兵数,而这个特征乘以10就是10分钟内所有小兵的击杀数,即blueTotalMinionsKilled。在后续的特征处理过程中,我们可以考虑去除这些冗余特征。
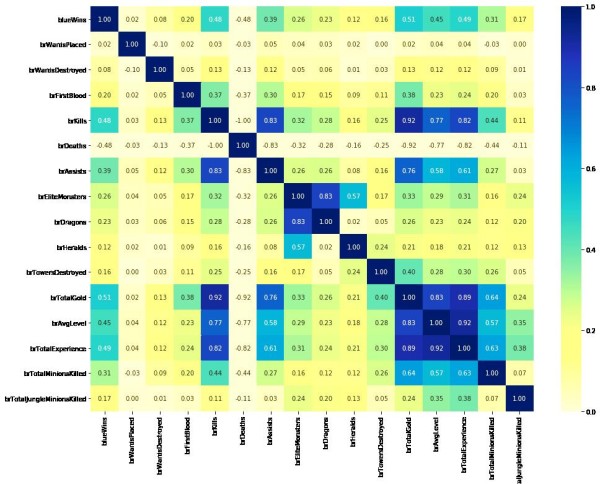
◇ 特征相关性分析与准备
另外,pandas提供的describe()函数非常实用,它可以轻松地展示每一列数据的统计信息。通过这个函数,我们可以对数据的分布情况有更全面的了解。例如,对于蓝色方的击杀英雄数(blueKills),在前十分钟的平均数是6.14,方差为2.93,中位数为6,且在超过百分之五十的对局中,该特征的值都在4到8之间。这些信息对于后续的数据分析和模型训练都非常有价值。计算特征之间的相关系数,评估特征的重要性,为模型选择合适的特征。
04模型构建与测试
◇ 模型训练与测试
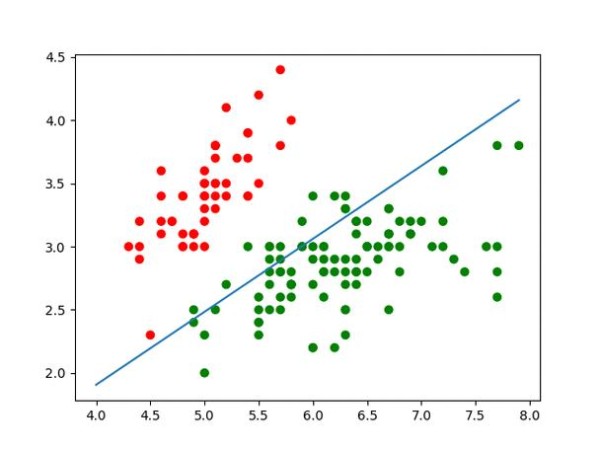
接下来,我们将简要介绍如何使用逻辑回归模型进行训练和测试。首先,我们初始化一个逻辑回归模型,并设定随机种子以确保结果的可重复性。然后,在训练集上对模型进行训练,并在测试集上进行预测以获得预测结果。最后,我们计算测试预测值与实际标签之间的准确率,并输出结果。
◇ 交叉验证与调优
在数据量相对较小的情况下,单次训练和测试可能无法准确评估模型的泛化能力。为了克服这一问题,我们通常需要重复多次训练和测试,并取平均值。一种常用的方法就是交叉验证。采用交叉验证提高模型泛化能力,通过调整参数优化模型性能。
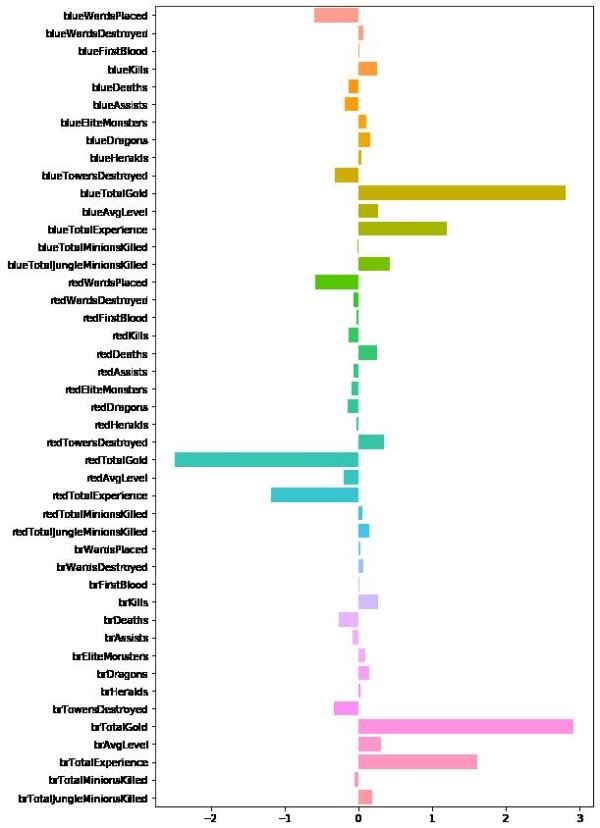
◇ 模型参数与结果解释
大多数机器学习模型在训练过程中会学习到一系列参数,这些参数在训练集上得到优化,以提升模型的预测性能。在scikit-learn库中,训练后的模型会提供一种机制来查看这些参数。以逻辑回归模型为例,一个关键参数是coef\_,它表示了每个特征对最终预测的贡献程度。在本例中,我们可以通过查看逻辑回归模型的coef\_参数来了解每个特征对分类预测的贡献。详细分析模型中各个参数的意义,评估特征对预测结果的贡献。
05总结与启示
完成一个机器学习任务,我们需要经历多个阶段,包括确定任务、数据分析、特征工程、数据集划分、模型设计、模型训练及效果测试、结果分析以及调优等。以英雄联盟游戏胜负预测为例,我们详细探讨了每个阶段的一些基本概念和实践方法,旨在为初学者提供一个清晰的机器学习入门指南。愿大家通过这个案例,能够深入理解机器学习的流程,并从中获得宝贵的实践经验。通过本案例分析,读者可以掌握机器学习在电子竞技数据分析中的应用,并获取实践经验。
举报/反馈
网址:电竞赛事分析:从数据中揭示英雄联盟全球总决赛的胜负 https://c.klqsh.com/news/view/301372
相关内容
2025英雄联盟全球总决赛2025年英雄联盟电竞赛事全新赛制与看点
2025年英雄联盟电竞赛事
全球十大电竞游戏深度解析:从《英雄联盟》到《APEX英雄》的
2025年英雄联盟电竞赛事信息
深入探讨英雄联盟电竞赛事国际赛事赛制
英雄联盟电竞赛事2024年展望
展望:2025英雄联盟电竞赛事
《英雄联盟》2025全球赛区观赛热度排行
2025全球总决赛:电竞赛事在中国的再度崛起
随便看看
最新乐趣
- 《奔跑吧》白鹿御用妆造全力上阵,输给章若楠素颜感
- 四代洗澡这段:你们敢说敢播我都不敢看不敢听
- 姜妍 娱乐评论大赏 微博VC计划微博VC计划
- 金刚狼的魅力在于解决问题的能力
- 唐山大地震:张子枫演技爆棚!短短几秒钟的回眸看哭太多人
- 马龙评论梁靖崑 梁靖崑参加活动被热议
- 胜意把牡丹给害惨,大福对她太失望,当场跟她割袍断义
- 站在粉丝角度看是真的会气得不行,正要听回答呢 一下子就切走了
- 《功夫女足》闯入路人镜头,热巴艾米素颜抗打,张艺兴反差太大
- 许君聪曾回应李成儒称周星驰不是墙角
热点乐趣
- 86827
- 64359
- 62063
- 54622
- 35754
- 31149
- 29988
- 22220
- 18785
- 17305

